Reading 1: Python Basics #
In this chapter, you will learn about the basics of writing code in Python. Even with the small amount of Python you learn here, you should be able to write short programs that will run on your computer.
This reading may seem a bit longer because we have tried to present many examples to help illustrate the concepts. As you read through this chapter, remember that we do not expect you to remember everything the first time - try to focus on understanding the broad concepts, and then refer back to the chapter as you go through exercises on the worksheet or assignment.
Running Python Code #
There are a few ways to run Python code, which we describe below. As you go through the rest of this chapter, we’d encourage you to run code you see to try it for yourself. You should also try making some mistakes so you can get a feel for the types of error messages you might get while programming.
The Python Interpreter #
One way to run Python code is to use the Python interpreter, which allows you to run individual statements of Python code. This is useful for quickly trying out small amounts of code.
You can start the Python interpreter by opening a terminal window and running
python. You should see something that roughly looks like this:
Python 3.8.5 (default, Jul 27 2020, 08:42:51)
[GCC 10.1.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>>
On some machines, running python will show the version as something like
Python 2.7.18, which is an older version of Python with significant
differences from the version of Python we use in this course. If this happens,
you should make sure that you have correctly followed our computational
setup.
In the Python interpreter, you can write lines of Python code and press Enter to execute them:
>>> 3 + 5
8
>>> print("Hello world!")
Hello world!
We will sometimes use this style to show the result of running a line of code.
You can use the Up/Down arrows to scroll through previous lines that you have
executed, which is useful if you accidentally mistype a line. To exit, run
exit() or press Ctrl-D.
Python Scripts #
If you write lines of Python code in a file, you can use the python command to
load and run all of the lines in that file in order, as if you had typed them
one after the other into the interpreter. Files containing Python code usually
end in .py. So suppose that you had a file called palindromic_square.py with
the following text in it:
ones = 111111111
square = ones * ones
print(f"{ones} squared is {square}")
(Don’t worry about understanding what the last line does for now.)
Then, running the command python palindromic_square.py would print the
following:
111111111 squared is 12345678987654321
In this course, you will write most of your code in files like these.
Jupyter Notebooks #
Another way to run Python is through Jupyter notebooks, which you have already seen in Reading 0. Each Jupyter notebook has a kernel, which you can think of as a Python interpreter running as a Web service in the background. The kernel runs code from a notebook’s code cells.
Using Jupyter notebooks requires a Web server to be running on your computer, so
to run or edit these notebooks, you will need to first start this server. To do
so, run the command jupyter notebook or jupyter lab in a new terminal
window. You are recommended to use a terminal window/tab just for this command,
since the server prints output as it runs. To shut down the server, press Ctrl-C
(and usually, you will then have to enter y to confirm).
On most machines, starting the Jupyter notebook server will automatically launch your Web browser with a window that allows you to select an existing file to open or create a new file, like this:

If not, you can look in the notebook server output for a link that looks like the following (note that the token value is an example, and will not work on your machine):
http://localhost:8888/?token=a995013330f6bb9d0546af78778c19a99a6400397e23e1fc
Jupyter notebook files have names ending in .ipynb (for interactive Python
notebook). If you open a notebook file, you will see an interface that looks
like this:
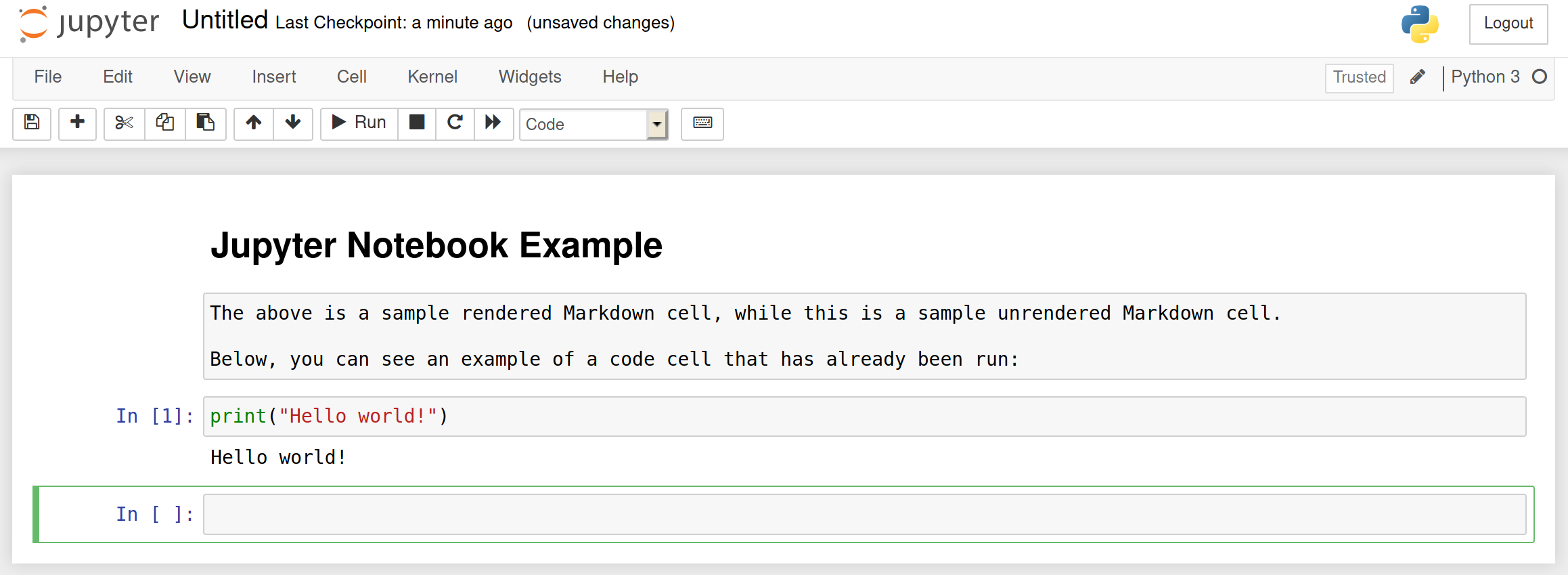
The number next to the code cell indicates the order in which you have run the
cells, while In: [ ] indicates that the cell has not been run yet. A cell can
be run multiple times, and the numbers will count up accordingly. Sometimes the
order in which you execute cells matters, so it can be helpful to double-check a
notebook when you are done with it by selecting “Run all” in the Cell menu. Note
that there is no way to “undo” the effect of running a cell, except to restart
the kernel from the Kernel menu.
Variables and Names #
The concept of variables is fundamental to computing, since it allows us to store and use data over the course of a program. This data can be simple values such as integers or can be code that executes as part of a program. In this section, we will provide an introduction to how variables work in Python.
Objects #
Objects are how Python represents data. An object consists of three things:
- An identity: where on your computer the object lives. We generally do not care about the identity of an object in this course.
- A type: what kind of data the object represents, like an integer, string or list. This determines what Python can do with the object.
- A value: usually, this is the actual data that we care about, like 42 or
"Olin".
As an example, consider the mathematical expression \(x = 42\) . We can say that it is an integer (its type) with the value 42.
If you find the concept of object representation in Python interesting and want to dive into the (very) deep end, you can take a look at the Python language reference, which has an entire chapter on how objects and data are represented. However, this is purely optional.
Variables vs. Objects #
A variable is basically an object with a name - a way for humans to refer to the object. Perhaps confusingly, we sometimes use the term identifier to refer to an variable name - this is not the same as an object’s identity.
Variable Names #
In Python, the rules for what can and cannot be a variable name are quite complex (this link is purely optional to read). For now, you should just remember a few rough guidelines for what can be a valid variable name in Python:
- Names should start with a letter or underscore:
f,hunter2and_secretare fine, but6ix9ineis not. - Names can contain letters, underscores, and numbers.
- Names cannot be keywords used in other parts of Python, such as
if,True, orwhile. The full list of keywords is here.
Using a name that doesn’t meet all of the above guidelines will probably result in an error:
>>> leading-digit = 1
File "<stdin>", line 1
SyntaxError: cannot assign to operator
Somewhat surprisingly, the rules allow _ by itself to be a valid variable name
in Python. In some contexts, it has a special meaning. If you (optionally) want
to see some of this for yourself, open up an interpreter or notebook, run a few
commands, and then see what the value of _ is.
Variable Name Style #
Knowing what a variable can have as a name is not the same as knowing what a variable should have as a name. Carefully chosen names allow you convey a great deal of meaning about the variable to other people reading your code.
Many programming language communities have norms or conventions about style, and
Python is no different. In Python, variable names should be generally be written
in snake case, which means all lowercase, with words separated by the
underscore character (_). This means you would write total_expenses instead
of totalExpenses like you might in a language like Java (this is called camel
case).
There are a few exceptions to this naming convention, but for now, the only one
you should remember is that if you are defining a constant, that is, a
variable whose value you will set once and never change in the program, you
should write its name in all caps (but still separating words with underscores).
For example, if you were simulating the orbit of the moon around the earth, you
could have a variable called EARTH_MASS, which you would set only once - the
earth’s mass is (hopefully) not changing in your simulation.
In addition to this convention, everyone has a different idea of what makes a “good” variable name, but here are a few that we use:
- Avoid single-letter names, except a few special cases. If you are looping
through a list of integers, using
iis fine, but if there is a way to reasonably describe your variable in words, you should prefer to do so. For example, instead of writingf = m * a, writeforce = mass * acceleration. - Avoid excessive abbreviation. The meanings of abbreviations depend on the
context and the area, and it’s easy to get confused. For example,
fncould be short for “function” or “false negative” - it’s easier to just write this out. - Avoid vague names. Variable names like
num,count, orvaluecan make code difficult to understand because they are all measuring something - it’s just not clear what from those names.
Though you might not understand all of it, we encourage you to take a look at other kinds of names to avoid in the Google Python Style Guide (about a paragraph).
It might be tempting to not follow these rules from time to time: many tutorials and forum posts, even otherwise very good ones, use variable names that are less than ideal. Try to build good habits now - it only gets easier as you keep doing so.
Creating and Changing Variables #
You can create a variable with an assignment statement, like this:
answer_to_life = 42
From this point in the program, you can use the name answer_to_life as 42:
# This sets some_prime_number to 43.
some_prime_number = answer_to_life + 1
You can change the value of a variable with another assignment statement:
answer_to_life = 3.14
Note that doing this does not change the values of things that have used that
variable (like some_prime_number), except in a few special cases that we will
see later.
Basic Types and Operators #
We will now take a look at a few basic types. Remember that a object’s type defines what you can do with the object. If a part of your program expects data of a certain type and instead gets data of a different type, it can crash with an error. These errors are inevitable, but with a good understanding of types, you will be able to quickly find and fix the relevant part of your code.
Along with these types, we will look at a few operators that you can use with them. Operators are essentially symbols that represent doing something with one or more values.
As you go through this section, we encourage you to run the code and explore a
bit on your own. If you ever want to see what type something is, you can use the
type function in the Python interpreter or in a Jupyter notebook like this:
answer_to_life = 42
# This will tell you that answer_to_life is <class 'int'>
type(answer_to_life)
# This will tell you that answer_to_life + 3.14 is <class 'float'>
type(answer_to_life + 3.14)
Integers and Arithmetic Operators #
As its name suggests, the integer type represents integer values (numbers with
nothing past the decimal point). You can get the additive inverse (negative) of
an integer by adding a - before the integer:
positive_int = 42
negative_int = -1
double_negative_int = -(-22)
You can do standard addition and subtraction with integers:
>>> 2 + 5
7
>>> 21 - 34
-13
You can also do multiplication and exponentiation, though the symbols look different from what you find in standard mathematical notation:
>>> 2 * 8
16
>>> 2 ** 8
256
As you might expect, the standard order of operations applies, so you may have to use parentheses to force operations to happen in a certain order:
>>> 3 * 7 + 2 ** 2
25
>>> 3 * (7 + 2) ** 2
243
In the first line above, the expression 2 ** 2 is evaluated to 4 first, and
then 3 * 7 is evaluated to 21. These are then added together to produce
25. In the second line, the expression 7 + 2 is evaluated first due to the
parentheses, which results in 9. Then, this value is used in 9 ** 2 to
produce 81, and finally, the multiplication 3 * 81 produces 243.
Division is a bit odd since dividing two integers does not always produce an integer:
>>> 5 / 2
2.5
The result of this division is a floating-point number, which we will discuss next. However, it is worth noting that dividing two integers always produces a floating-point number, even if the result would ordinarily be an integer:
>>> 5 / 1
5.0
This behavior might seem unintuitive, but can be helpful when reasoning about a
program’s behavior. Because dividing two integers always produces a floating-point
number, if you have integers a and b and write a line like c = a / b, you
know that c is always a floating-point number, regardless of whether b
divides a or not.
If you want the division of two integers to instead produce an integer, you can
use the floor division operator, written //:
>>> 24 // 4
6
This operation is called floor division because it always rounds the result down to the next integer:
>>> 5 // 4
1
>>> 6 // 4
1
>>> 7 // 4
1
>>> 8 // 4
2
The remainder operator, written as %, is related to the floor division
operator, giving the remainder of dividing two integers:
>>> 5 % 4
1
>>> 6 % 4
2
>>> 7 % 4
3
>>> 8 % 4
0
The remainder operator is sometimes called the modulo operator or simply mod for short, but this term can be confusing because some people (and programming languages) assume that the modulo operation must produce a positive number, whereas in Python, it does not:
>>> 13 % 4
1
>>> -13 % 4
3
>>> 13 % -4
-3
>>> -13 % -4
-1
In Python, you can assume that a % b will always produce an integer between 0
and b, excluding b itself.
Floating-Point Numbers #
Floating-point numbers, sometimes simply called floats, are a type that represent numbers with a decimal point. The term “floating point” refers to the fact that the decimal point can “float” among the digits: you can have a float with one digit past the decimal point, and another float with 22 digits past the decimal point.
Floats support all of the arithmetic operations that integers do, but note that arithmetic with floats can sometimes have surprising results:
>>> 0.1 + 0.2
0.30000000000000004
This is due to the way that Python (and many other programming languages) represents floating-point numbers. Essentially, computers have small rounding errors with floats, which can sometimes lead to surprises like this.
If you want to read more about arithmetic with floating-point numbers in Python, you can see this official tutorial, though this is completely optional.
Booleans #
The boolean type has only two possible values: True and False.
(Capitalization is important here - true or false will not work.) Booleans
represent the truth of logical statements, and are used in all but the simplest
programs.
Comparison Operators #
You can set the values of boolean variables directly:
checked_out = True
But more often than not, this is done with comparison operators, which allow you to compare two values and determine whether that comparison is true or false. The basic comparison operators are:
- Equality (
==):Trueif the two sides are equal. - Inequality (
!=):Trueif the two sides are not equal. - Less than (
<):Trueif the left side is less than the right. - Greater than (
>):Trueif the left side is greater than the right. - Less than or equal to (
<=):Trueif the left side is less than, or equal to, the right. - Greater than or equal to (
>=):Trueif the left side is greater than, or equal to, the right.
Here are a few examples you can run in your interpreter:
>>> 2 + 2 == 5
False
>>> 3 != 3.14
True
>>> 2 ** 10 > 1000
True
>>> -2 ** 8 < 0
False
As you see in the second example, you can compare different types.
Here is a slightly longer example:
celsius = -40
fahrenheit = (celsius * 1.8) + 32
# Because the two values are equal, both of these are True.
celsius <= fahrenheit
celsius >= fahrenheit
Surprises in floating-point arithmetic can affect comparisons, too:
>>> 3 < (0.1 + 0.2) * 10
True
Logical Operators #
Just like you can combine numbers with arithmetic operators like + and **,
you can combine booleans with logical operators. Python’s logical operators are
easy to read: they are just the words and, or, and not. Here are some
examples:
x = -4
y = -3
# Both of these need to be True for the whole thing to be True, so this is
# False.
x + y > 0 and x * y > 0
# Only one of these needs to be True for the whole thing to be True, so this is
# True.
x - y < 0 or y - x < 0
# You could write this with !=, but this is just an example, and is True.
not x == y
Sometimes, when using and, you might use the same value twice:
1970 < current_year + 1 and current_year + 1 < 2038
For convenience, you can combine these two like this:
1970 < current_year + 1 < 2038
You can chain together comparisons like this as much as you like, but we discourage it, because it can be hard to read or understand:
new_warnings == total_warnings > total_errors <= total_messages
Strings #
The string type represents text, like 'Trogdor' or "BURNiNATOR". It
doesn’t matter whether you use single quotes (') or double quotes ("), as
long as they match.
You can have a string with nothing in it called the empty string. It is
written as "".
Escaping #
If you need to use a quote mark within a string, you can precede it with a
backslash (\). This is called escaping the quote mark, because you
temporarily “escape” Python looking for the end of the string. Note that you
only need to escape quote marks that match the ones you are using for the string
itself:
>>> "Dorothy said, \"There's no place like home.\""
'Dorothy said, "There\'s no place like home."'
To minimize escaping, we use double quotes for strings in this course, since single quotes (as apostrophes) show up in strings more often.
Escaping can be used to put other special characters into strings. For example,
\n represents a line break and \\ represents an actual backslash in the
string. You can see a table of all of these in the official Python
language reference.
Basic String Operators #
You can compare two strings to check if they are exactly equal (sensitive to case, spacing, etc).
You can also “add” two strings together:
# Set greeting to "Hello world!"
greeting = "Hello " + "world!"
This is called concatenation. Notice that spaces are not automatically added,
so we had to do it ourselves in "Hello ".
You can repeat a string by multiplying it by an integer:
# Set laugh to "hahahaha"
laugh = "ha" * 4
You can check whether a character or sequence of characters is in a string by
using the in operator, but note that this is case sensitive:
>>> "ah" in "hahahaha"
True
>>> "hello" in "Hello world!"
False
The empty string is in every string, including itself:
>>> "" in "everything"
True
>>> "" in ""
True
The opposite of in is not in, like "foo" not in "bar".
f-strings #
Sometimes, you want to use the value of a variable as part of a string:
personalized_greeting = "Hello, " + name + "!"
It can be tricky to remember to put spaces in the right place, and if you want to include the value of an integer in the string, you have to convert it into a string first (which you will see later in this reading).
You can solve both of these issues with an f-string:
personalized_greeting = f"Hello, {name}!"
It gets its name from the f right before the opening quote. This is much
cleaner and less likely to issues like missing spaces. You can also include
numbers, and in fact entire code expressions in an f-string, and you can do this
multiple times in the f-string:
age = f"I am {current_age} now but I will be {current_age + 1} next year."
Indexing and Slicing #
You can get an individual character of a string by using square brackets ([])
with an integer, like this:
school = "Franklin W. Olin College of Engineering"
# This is "r"
school[1]
This called called indexing a string, and in this example, the number 1 is called the index.
You may be surprised to see that school[1] gives you the second character of
school instead of the first. In Python, the index of strings and other types
start from 0, so the
\(i\)
th character of a string is at
index
\(i - 1\)
. It may be helpful to think of the index
as how many characters you are away from the first character in the string.
Using a negative integer as the index will give you a character counting from the end of the string, with the index \(-1\) referring to the last character of the string.
Here is an example string that shows the indices corresponding to each character, with positive indices on top and negative indices on bottom:

If you try to access an index outside of this range (i.e., an index greater than 6 or less than -7 in the image above), you will get an error message that looks like this:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: string index out of range
If you want to get multiple characters out of a string at once, you can do something like the following:
advice = "Use the Force"
# This gives you "the"
advice[4:7]
This is called slicing a string, and the portion of the string you get back is
called a slice. The two indices can be negative as well, like advice[-9:-6].
You might be a bit surprised to see that the character at the second index is not included in the slice - in other words, you get the portion of the string including the first index up to the second index. Here is example that shows this more intuitively:

One nice thing about doing string slices this way is that the difference between
the two indices is the number of characters you get back (so advice[4:7] gives
you 3 characters).
You can provide a starting and ending character position, but you do not have
to. If you do not provide a starting character position, it will be assumed to
be 0, and if you do not provide an ending character position, you will get the
rest of the string from your start point. So in our advice example above,
advice[:3] would give you "Use", while advice[-5:] would give you
"Force".
If you give an invalid pair of starting and/or ending positions, you will get an empty string:
>>> advice[3:1]
''
>>> advice[100:]
''
You can also provide a second colon (:) along with another integer (called the
step size) to take every
\(n\)
th character:
>>> advice[::2]
'UeteFre'
As you can see, this takes the entire string, but only every other character, starting from the one at position 0.
As with a regular string slice, you will get the subset of characters up to, but not including, the end position. The number of characters between the start and end position does not have to be a multiple of the step size - you will simply get the characters that you can:
>>> advice[1:7:3]
'st'
>>> advice[1:8:3]
'st '
>>> advice[1:10:3]
'st '
Finally, you can also use a negative step size:
>>> advice[::-1]
'ecroF eht esU'
This example is a handy way to reverse a string. You may notice that the start and end positions have been “switched” in the sense that they now run from right to left:
>>> advice[:-6:-1]
'ecroF'
Conditionals #
A conditional allows you to execute certain Python code based on certain factors such as whether a variable has a certain value.
The if Statement
#
Similar to the English language, Python uses the word if to denote a
conditional block of text. We then have a boolean expression to evaluate, that
if true we will then execute the code block below it.
x = 42
if 42 % 6 == 0:
y = 1
if x % 5 == 0:
y = 2
z = -1
In the example above, y will be set to 1 because x % 6 is 0. But y will
not be set to 2, and z will not be created at all, because x % 5 is not 0.
You can put multiple lines under an if statement, and it will execute all of
them if the condition is True. The lines all need to be indented by the same
amount. In this course, we use 4 spaces to indent a line.
You can also nest if statements inside one another.
if x % 3 == 0:
y = 1
if x % 2 == 0:
z = -1
This will set y to 1 and z to -1.
The else Statement
#
You can use an else statement with an if statement to cause code to run when
the if block does not:
if keypad_input == user_pin:
grant_access = True
else:
activate_alarm = True
In this example, activate_alarm is set if the grant_access = True line does
not run, which only happens when the condition is false.
Note that an else statement cannot run on its own - there has to be some
condition not fulfilled for the statement’s code to run.
The elif Statement
#
Sometimes, you want to have several possible conditions and do something
different in each scenario, like set a string with the someone’s birth month,
based on the number of the month. If you write this with just if and else,
you would end up with the following:
if birth_month == 1:
written_month = "January"
else:
if birth_month == 2:
written_month = "February"
else:
if birth_month == 3:
# And so on...
Or, to give a real-life analogy:

To avoid, this you can use an elif statement, which allows you to combine an
else and if. The above code would be written this way with an elif:
if birth_month == 1:
written_month = "January"
elif birth_month == 2:
written_month = "February"
elif birth_month == 3:
# And so on...
This is a cleaner and more readable way to write the same code.
Like an else, an elif needs to have an if statement before it, since it
only checks its condition when the preceding if statement is not satisfied.
You can put an else statement at the end of a block of if and one or more
elifs:
if in_inventory == 0:
response = f"You have no {item}s."
elif in_inventory == 1:
response = f"You have a {item}."
else:
response = f"You have {in_inventory} {item}s."
Functions #
Functions are a central piece of Python programming. They essentially allow you to store code and use it multiple times in different contexts. By packaging your code up in functions, you will have an easier time writing and maintaining your code.
Anatomy of a Function #
You can think of a function as having four key components:
- It has a name, so that you can refer to it.
- It may have parameters, which are pieces of data that you give to it when running it.
- It may have side effects, which are things that the function “changes” outside of itself as it runs (more on this later).
- It may have a return value, which is data it gives back to you after it has finished running.
It is helpful to build up the skill of identifying these four things in a function when you see one.
With that in mind, let’s take a look at a very simple example function:
def reverse(word):
return word[::-1]
The function’s name is reverse. It takes one parameter, word, which in this
case is probably a string. It returns word[::-1], which is a string that is
the reverse of word, so it does what it says.
The return keyword determines what the return value of the function is. In
this case, the function computes word[::-1] and that becomes the return value.
Once a return statement runs in a function, the function immediately stops, so
you can use this to end a function early (like in an if statement).
You might be surprised to hear that reverse has no side effects. Isn’t it
reversing the string word? It is, but when you do something like word[::-1],
you are actually creating a copy of word and reversing that, which allows you
to use the original word in other parts of your code.
So what is a side effect, then? What does it mean to change something outside of
a function? There are a handful of functions that change the value of existing
variables when they run instead of making a copy of the variables - this is a
side effect. The print function (which we will see in just a moment) is a very
commonly used function that displays text on the screen - printing to the screen
is also a side effect. We will identify other functions with side effects as we
introduce them, but for now, you should just remember these two examples of side
effects.
Calling a Function #
Using the function by running its code is called calling the function. You can call a function like this:
# This will return the string "olleH"
reverse("Hello")
In this example the string "Hello" is called an argument to reverse. This
might be a subtle distinction, but you can think of a parameter as a name and
type, and an argument as a value.
You can take the return value of a function you have called and assign it to a variable:
# This sets the value of backwards_greeting to "olleH"
backwards_greeting = reverse("Hello")
In this case, we usually say that reverse takes "Hello" as an argument and
returns the string "olleH".
Docstrings #
A docstring is a special string used to explain the behavior, parameters,
return value, and side effects of a function in human-readable form. (Other
things in Python can have docstrings, but we will discuss those later.) In our
reverse example, from above, a docstring would look something like this:
def reverse(word):
"""
Return a reversed copy of a word.
Args:
word: A string representing the word to reverse.
Returns:
A string containing the characters of word in reverse order.
"""
return word[::-1]
Notice that we start and end a docstring with three quote marks, and that the docstring is indented to the same level as the function’s code.
The actual format of the docstring can vary quite a bit, but we use a format almost identical to Google’s docstring style (optional reading). In a nutshell, you should remember the following guidelines:
- The first line of the docstring is a single sentence that describes what the function does. If the function is complex, you can add more paragraphs underneath that line to explain what it does.
- The Args section lists each parameter and mentions its type and what its value represents. If your function has no parameters, you can omit this.
- The Returns section lists the type of data the function returns and what its value represents. If your function does not have a return value, you can omit this.
In the assignment, you will get the chance to practice writing some docstrings.
While docstrings are primarily written for each individual function (or class - as you will see in the future), each module - or file containing python code - also requires documentation; this can be as simple as a sentence or two describing the contents of the file typically in the following format:
"""
Sentence or two describing overall contents of module.
Any additional relevant details regarding the file including, but not limited to
exported classes (introduced later) & examples of how to use the contents of the
file.
"""
For example, a file containing a file containing multiple operations on various strings - such as reverse - might look like this:
"""
Basic string modification functions.
"""
The pass Statement
#
You should write function docstrings before the main body of the function. This allows you to think through what the function does (its inputs, outputs, side effects, etc) before you write it.
This is where the pass statement comes in handy.
def factorial(number):
"""
Return the factorial of a given number.
Args:
number: An int representing a number to compute the factorial of.
Returns:
An integer representing N factorial.
"""
pass
The pass statement is a placeholder. Python does nothing upon encountering
it. It is useful for representing an unwritten block of code, such as the body
of a function.
Common Functions #
A few functions are used often enough in Python that you should become familiar with them even as a beginning programmer.
The print Function
#
The print function is almost certainly the most commonly used function in
Python - most people’s first less in writing Python is to write print("Hello world!"). Usually, the print function takes a string and displays it to the
screen. (It can take more parameters, but we will see those later.)
The print function has the side effect of printing a string to the screen, but
it does not have a return value. You can see this if you try to assign it to a
variable:
# This prints "Hello world!" but sets print_return to None
print_return = print("Hello world!")
We will see more about the special value None in a future reading, but for
now, if you see an error mentioning 'NoneType', you may have accidentally
tried to use the return of a print function, like this:
def show_reverse(word):
print(word[::-1])
word = "Hello"
# This results in an error because show_reverse has no return value
palindrome = word + show_reverse(word)
The len Function
#
The len function simply tells you how long certain objects are. For now, you
should assume that you can only call len with strings to find out how many
characters they have, like this:
# This returns 12
len("Hello world!")
# This returns 0
len("")
In later chapters, you will see other types that you can pass to len.
Type Conversions #
Sometimes, you might have a float like 5.0 and want to use it in a function
that needs an integer. You can convert the float into an integer like this:
# This returns 5
int(5.0)
There are functions to convert objects into the types we have already seen:
integers (int), floating-point numbers (float), booleans (bool), and
strings (str).
You cannot convert any object to these types - for example, int("Hello world!") does not work (and frankly, does not make much sense).
The help Function
#
The help function takes a function as a parameter and displays its name,
parameters, and docstring. For example, if we loaded the definition for
reverse above, then running help(reverse) (notice there are no quotes around
reverse) would print the following:
Help on function reverse in module __main__:
reverse(word)
Return a reversed copy of a word.
Args:
word: A string representing the word to reverse.
Returns:
A string containing the characters of word in reverse order.
In an interactive Python environment like the interpreter or a Jupyter notebook,
using help is a good way to refresh your memory of what a function does or to
help you learn.
Bugs #
Initially you will likely encounter two type of bugs in Python: syntax errors and runtime errors (also called exceptions).
Syntax Errors #
In programming languages, syntax refers to the set of rules about what
constitutes a valid statement. This term is also used in linguistics - a valid
(syntactically correct) English sentence needs to start with a capitalized word
and end in a period, question mark, or exclamation point. Note that syntax has
nothing to do with the correctness of the code itself, or whether the code will
even run successfully. “Colorless green ideas sleep
furiously.”
is a valid sentence using the rules of English syntax but doesn’t have a widely
agreed-upon meaning, and the statement x += 42 on its own is a valid Python
expression but won’t execute successfully because x does not have a value.
When you try to run code in Python, the interpreter checks the text of the code to try to split it into a series of statements that it can then execute. If this process fails, you get a syntax error. Try running the code below in a Jupyter notebook:
print("Hello world!")
x = (4, 5
As expected, we get a syntax error. Notice that when you get a syntax error,
none of the code runs, even if the code before the error is fine (like the
print function call above).
If we ran this code in the Python interpreter, we’d see this:
>>> print("Hello world!")
Hello world!
>>> x = (4, 5
...
The interpreter would wait for you to close the parentheses and use the ... to
denote an unfinished block of code. You are be able to add the closing
parenthesis and have the code run correctly.
When encountering an error, it’s also important to pay attention to two pieces of information when you get an error: the location of the error, and the error message.
The location of the error consists of a file, line number, and position in that
line. In a Jupyter notebook, the file is "<ipython-input-...>" (which is the
format for cells in a Jupyter noteook) and in the Python interpreter, the file
is "<stdin>". In a regular .py file, this would be the name of the file
itself. The line number tells you where in the file the error occurred, and the
caret (^) shows you where in the line the error occurred. It’s worth noting
that the caret will point to the spot where Python first detects that there
must be a syntax error, not necessarily to the location that needs to be fixed.
Take a look at this example:
x = (1,
y = 5
If you ran this in a Jupyter notebook, you would get the following output:
File "<ipython-input-1-a60693365e48>", line 2
y = 5
^
SyntaxError: invalid syntax
Notice that it isn’t until = that the Python interpreter knows this must be a
syntax error - for all it knows, y could have been defined and part of a
larger expression.
The error message can sometimes give you a helpful clue as to what has gone wrong. In the first example above, you should have gotten the error message “unexpected EOF while parsing” (EOF stands for end of file). This message tells you that as the Python interpreter was scanning to find the end of the tuple, a collection of several pieces of data you will learn about later.
However, sometimes the error message is less helpful: in the second example
above, you should have only gotten the message “invalid syntax”, which provides
almost no additional information. As a helpful tip, the message “invalid syntax”
almost always means that you forgot to close a paired delimiter (i.e., you left
out a ), ], or }) or that you left out a colon (:) at the end of a
statement starting with if, for, while, etc.
Finally, note that in addition to SyntaxError, there is another type of syntax
error you may encounter: IndentationError. You have probably noticed that when
you start an if or similar statement, end it with a colon, and press Enter,
the next line will be indented by 4 spaces. (The actual number of spaces does
not matter, as long as you are consistent.) An IndentationError indicates that
a line of code is indented in an unexpected amount (too few or too many spaces).
Exceptions #
Runtime errors or exceptions are errors that occur while code is running. Most non-syntax errors that cause the code to stop running will fall into this category.
Exceptions in Python can happen for a large possible number of reasons. When you
encounter an exception, the most helpful step is usually to read the error
message to understand exactly what happened. That being said, the most common
errors you will see at this point are likely NameError (the variable or
function that you are trying to use has not been defined yet) or TypeError
(you mistakenly tried to do something like add an int to a string).
You can find a complete list of built-in exceptions here. You do not have to be familiar with all of these, but it is helpful to look up exceptions as you run into them and familiarize yourself with what specifically these exceptions mean.
If you encounter an exception, there are a number of things you can check that may help you find the bug:
- Make sure you didn’t make a typo. If you get a
NameErrorfor a name you thought you defined, it is likely that you either deleted that name, or misspelled its name. - Check your types. Getting a
TypeErrormeans you are trying to call a function or operation on the wrong data type. You are either calling a function on the wrong variable, or mistakenly assigned the wrong data to a variable. Having good and clear variable names helps avoid potential confusion. Checking the places you are assigning to the variable can help track down the errant line of code. - Make sure you have updated your code correctly. For example, if at various
points you strip out the first 4 characters of a string like
foo[4:]and use this in multiple places, make sure that whenever you change this in one place, you change it in others as well. Better yet, define a function or variable for things like this so that you only have to change it in one place.
Semantic Errors #
Perhaps the trickiest type of bug to find in code are semantic errors. You will write code that has perfectly correct syntax, but still does not have the intended result. This is a semantic error, a bug where your code is not doing what you think it is.
For example, let’s say you’re making a video game. The program runs fine, but for some reason your character is not showing up on screen. You look at the game’s draw routine, and you notice your character’s sprite is being drawn before the background. Thus, the background is not actually in the back! It has become the foreground placed in front of everything.
Here’s an simple example of some code with a semantic error:
def square(number):
"""
Return the square of a given number.
Args:
number: An int representing a number to compute the square of.
Returns:
An int representing N squared.
"""
return number * 2.
If you typed this function into the Python interpreter, you would see the following results:
>>> square(2)
4.0
>>> square(3)
6.0 # Uh oh
You may notice the line above says number * 2. rather than number ** 2,
which results in the incorrect behavior. A more subtle error is the return
type. The function docstring specifies taking an int as an argument and
returning an int; however, it’s returning a float, indicated by the decimal
point. This is due it using 2. instead of 2, a subtle difference.
Semantic errors become harder to track down as you write larger and more complicated programs. Fortunately, there are many powerful tools you can use to chase down these errors. You will learn about several of these later in this course.